
Caffeine is powered by SqueakJS. The performance of SqueakJS is amazingly good, thanks in large part to its dynamic translation of Smalltalk compiled methods to JavaScript functions (which are in turn translated to machine code by your web browser’s JS engine). In the HTML5 environment where SqueakJS finds itself, there are several other tactics we can use to further improve user interface performance.
Delegate!
In a useful twist of fate, SqueakJS emerges into a GUI ecosystem descended from Smalltalk, now brimming with JavaScript frameworks to which SqueakJS can delegate much of its work. To make Caffeine an attractive environment for live exploration, I’m addressing each distraction I see.
The most prominent one is user interface responsiveness. SqueakJS is quite usable, even with large object memories, but its Morphic UI hasn’t reached the level of snappiness that we expect from today’s web apps. Squeak is a virtual machine, cranking away to support what is essentially an entire operating system, with a process scheduler, window system, compiler, and many other facilities. Since, with SqueakJS, that OS has access to a multitude of similar behavior in the JavaScript world, we should take advantage.
Of course, the UI design goals of the web are different than those of other operating systems. Today’s web apps are still firmly rooted in the web’s original “page” metaphor. “Single Page Applications” that scroll down for meters are the norm. While there are many frameworks for building SPAs, support for open-ended GUIs is uncommon. There are a few, though; one very good one is morphic.js.
morphic.js
Morphic.js is the work of Jens Mönig, and part of the Snap! project at UC Berkeley, a Scratch-like environment which teaches advanced computer science concepts. It’s a standalone JavaScript implementation of the Morphic UI framework. By using morphic.js, Squeak can save its cycles for other things, interacting with it only when necessary.
To use morphic.js in Caffeine, we need to give morphic.js an HTML5 canvas for drawing. The Webpage class can create new DOM elements, and use jQuery UI to give them effects like dragging and rotation. With one line we create a draggable canvas with window decorations:
canvas := Webpage createWindowOfKind: 'MorphicJS'
Now, after loading morphic.js, we can create a morphic.js WorldMorph object that uses the canvas:
world := (JS top at: #WorldMorph) newWithParameters: {canvas. false}
Finally, we need to create a rendering loop that regularly gets the world to draw itself on the canvas:
(JS top)
at: #world
put: world;
at: #morphicJSRenderingLoop
put: (
(JS Function) new: '
requestAnimationFrame(morphicJSRenderingLoop)
world.doOneCycle()').
JS top morphicJSRenderingLoop
Now we have an empty morphic.js world to play with. The first thing to know about morphic.js is that you can get a world menu by control-clicking:

Things are a lot more interesting if you choose development mode:

Take some time to play around with the world menu, creating some morphs and modifying them. Note that you can also control-click on morphs to get morph-specific menus, and that you can inspect any morph.

Also notice that this user interface is noticeably snappier than the current SqueakJS Morphic. MorphicJS isn’t trying to do all of the OS-level stuff that Squeak does, it’s just animating morphs, using a rendering loop that is runs as machine code in your web browser’s JavaScript engine.
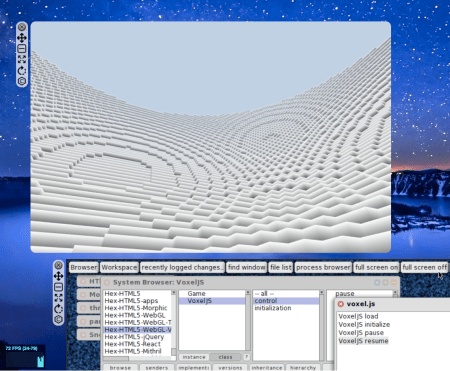
Smalltalk tools in another world, with Hex
The inspector gives us an example of a useful morphic.js tool. Since we can pass Smalltalk blocks to JavaScript as callback functions, we have two-way communication between Smalltalk and JavaScript, and we can build morphic.js tools that mimic the traditional Squeak tools.
I’ve built two such tools so far, a workspace and a classes browser. You can try them out with these expressions:
HexMorphicJSWorkspace open. HexMorphicJSClassesBrowser open
“Hex” refers to a user interface framework I wrote called Hex, which aggregates several JavaScript UI frameworks. HexMorphicJSWorkspace and HexMorphicJSClassesBrowser are subclasses of HexMorphicJSWindow. Each instance of every subclass of HexMorphicJSWindow can be used either as a standalone morphic.js window, or as a component in a more complex window. This is the case with these first two tools; a HexMorphicJSClassesBrowser uses a HexMorphicJSWorkspace as a pane for live code evaluation, and you can also use a HexMorphicJSWorkspace by itself as a workspace.
With a small amount of work, we get much snappier versions of the traditional Smalltalk tools. When using them, SqueakJS only has to do work when the tools request information from them. For example, when a workspace wants to print the result of evaluating some Smalltalk code, it asks SqueakJS to compile and evaluate it.
coming up…
It would be a shame not to reuse all the UI construction effort that went into the original Squeak Morphic tools, though. What if we were to put each Morphic window onto its own canvas, so that SqueakJS didn’t have to support moving windows, clipping and so on? Perhaps just doing that would yield a performance improvement. I’ll write about that next time.
 We’ve seen a couple of examples of frontend Caffeine development, using
We’ve seen a couple of examples of frontend Caffeine development, using 

 Since
Since  For the impatient…
For the impatient… 
