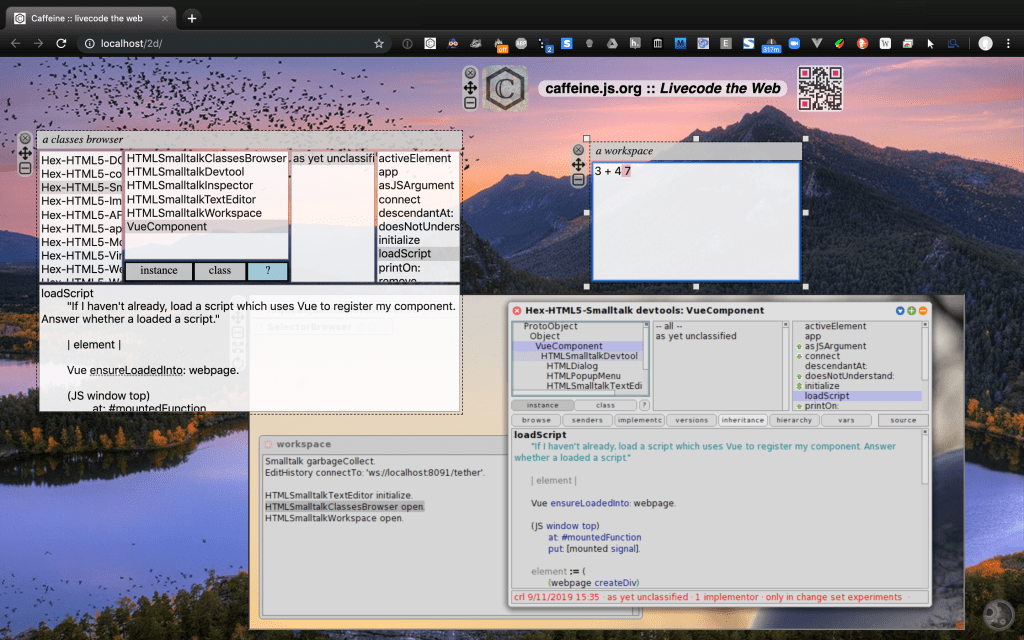
I’m writing phase four of the Catalyst Smalltalk virtual machine, producing a WASM GC version of the virtual machine from a Smalltalk implementation. WASM GC is statically typed. While I prefer the dynamically-typed livecoding style of Smalltalk, I want the WASM GC representation to be thoroughly idiomatic. This presents an opportunity to revisit the process of generating code from the virtual machine simulation; we can use the simulation to be precise about types, while livecoding Smalltalk as before.
imprinting returns
As part of earlier work I did to produce a minimal object memory, I developed a facility for imprinting behavior (methods) onto one system from another, as a side-effect of running them. We can use a similar technique to imprint the methods of a virtual machine simulation onto WASM GC code files. This affords some interesting possibilities. If we construct a minimal object memory as part of the simulation, we can ensure the virtual machine is also minimal, containing only the code necessary for running that object memory. That might have useful security properties.
We also have the traditional correctness proof that a virtual machine generated from its simulation gives us. The generated virtual machine can run that object memory, since the simulation could run it. But by imprinting the generated virtual machine from a running simulation, rather than statically, we have also have a stronger proof of type correctness. We don’t need to infer types, since we have live objects from the simulation at hand. This lets Catalyst take full advantage of the optimizations in the WASM GC development environment (e.g., ‘wasm-opt‘) and runtime environment (e.g., V8). It’s also easier to create fast virtual machines for particular debugging situations; you can change a running simulation that has come upon a problem, and generate the corresponding WASM virtual machine module quickly.
the details
This approach is enabled by more of my previous work. The interpretation of compiled methods is done by reified virtual machine instructions (“bytecodes”). Those instructions are initialized using the Epigram parsing and compilation framework I wrote. Epigram uses reified BNF grammar production rules to parse source code, and to form an abstract syntax tree. Each instruction has a code generator object corresponding to the language element it manipulates (e.g., an instance variable). Each code generator has a copy of the production rule that justifies the existence of the language element.
For example, in the Smalltalk grammar, a pseudo-variable reference (“self”, “super”, or “thisContext”) is parsed by the PseudoVariableReference production rule, a shared variable in a pool dictionary of Smalltalk production rules. A ReturnReceiver instruction has a SmalltalkReceiver code generator, which in turn has a copy of the PseudoVariableReference rule. Production rule copies are used to do the actual work of parsing a particular source; they hold parsed data (e.g., the characters for “self”), also known as terminals. The original production rule objects exist solely to define a grammar.
After being initialized from the rules used to parse the source code of a Smalltalk method, instruction objects can assist a virtual machine and its active context with interpretation. They can also generate source code, either in Smalltalk or some other language, with the assistance of their code generators. For WASM GC, code generation happens during interpretation, so that the types of all variables and return values are known concretely, and generation can be contingent on successful type validation.
type annotation and representation
For this approach to work, we need a source for that type information. I use pragmas contained in the methods of the simulation. Each Smalltalk method that will be translated to a WASM GC function has a pragma for each parameter and temporary variable, and another for the return value (if the WASM GC function is to have a return value). Every Smalltalk method leaves an object of some sort on the stack, even it’s just the receiver, but a WASM GC function may not.
A typical temporary variable pragma looks like this:
<local: #index type: #i32 attributes: #(mutable nullable)>
This corresponds to the semantics of local variables in a WASM GC function. Each one is declared with the “local” WASM GC instruction, and has a name, a type, and two attributes. A variable is mutable if its value can be changed after initialization, and nullable if its value can be null (a null of an appropriate type, of course). A variable can either have or not have each of those attributes.
WASM GC has a few built-in types, like “i32” for 32-bit integers. For reference (pointer) types, we write “(ref $type)”, where “type” is defined elsewhere in the source file. We define reference types for each kind of structure (“struct”) we’ll be using in the simulation, also by using method pragmas. Each class in the simulation has a “type” method which defines those pragmas. Just as there’s a format for variable type annotation pragmas, there’s another for struct type annotation, using “field:” instead of “local:”.
When we send “type” to a struct class, we get a type signature, a specialized dictionary created from those pragmas. A signature object is similar to a JavaScript object, in that we can send a message named for a desired field’s key, and the signature will answer the value it has for that key. Signatures are ordered dictionaries, since the order of variables in a function or fields in a struct type is crucial. Unlike JavaScript objects or Smalltalk dictionaries, signatures can have multiple values for the same key. This enables us to evaluate an expression like (VirtualMachine type field) to get an OrderedCollection of the fields in VirtualMachine’s type signature.
Signature objects are implemented by classes descended from PseudoJSObject, a Smalltalk implementation of JavaScript object semantics that inherits from OrderedDictionary. There are further specializations for different kinds of signatures, for functions, variables, and structs.
virtual machine generation in action
The preliminaries of the WASM GC source file for the virtual machine are written by the VirtualMachine itself. This includes all the reference type definitions, and definitions for functions and variables that Catalyst will import from and export to a webpage that’s running it. It also includes translations of the methods used to create the object memory. After interpretation begins, every time the VirtualMachine is about to interpret an instruction, it translates the methods run to interpret the previous instruction.
The VirtualMachine knows which methods have been run by using the method-marking facility I wrote about in “The Big Shake-Out”. When the system runs a compiled method, it sets a field in the method to an increasing counter value. In the object memory, one can ask the method for the value of that field, and one can set the field to zero. We can zero that field in every method at some initial time, run the system, and get a collection of every method that was run in the meantime, ordered by how recently they were run.
exemplar object memories
The object memory I’m running in the simulation is the same one I created in the initial handwritten version of the WASM GC virtual machine. It runs a simple polynomial benchmark method that could be optimized into a much more efficient WASM GC function by AI, and also demonstrates method caching and just-in-time compilation. We could develop formalisms for composing this object memory. Through the rigorous use of unit tests, we could produce object memories that exercise every instruction and primitive exhaustively, and act as minimal harnesses for benchmarks.
next: phase five, object memory snapshots
After the WASM GC virtual machine is free of handwritten WASM GC code, I’ll implement the ability to write and resume object memory snapshots. See you then!